I've noticed quite a few people voice their opinions on the difficulty of the second test, some even requesting that the mark be removed because they did so poorly. Of course this will not happen, the class is lucky enough to receive a grade bump to make up for the poor raw mark. My experience with the test was not as bad compared to most. I managed to get the test finished in 40 minutes and got a decent mark. The questions were reasonable and mostly focused on the ability to reflect your knowledge of recursive ADT's.
However I feel that the test should be a learning experience for those who took it so hard. You should not be devastated because you did poorly (or failed) a test worth at the least, 7%, of a credit that is worth 2.5% of the 20 credits you will take at a university you spend 5-8% of your life. This should be understood at all levels of a university course, whether it is a paper, test, assignment, or exam. Failure should not be something to avoid, rather something that should be embraced. Aiming for perfection is fine, but expecting it is dangerous to yourself. There is always an opportunity around the corner (such as the exam in our case) to make up for the failure.
This of course should be recognized in computer science to an even greater extent. You should not expect perfection in the real world.
Thursday 3 April 2014
Monday 31 March 2014
POST #7: Sorting and Efficiency
This week we are required to touch on sorting and efficiency--thus I will be discussing some sorting algorithms and how they are analyzed through Big-O.
Big-O
Before looking at the algorithms I should establish an idea of what Big-O is (to my understanding) and how we use it to analyze algorithms.
Big-O attempts to take away the little details of mathematical analysis of something like sorting or searching and sum it up in an abstract notation of 'O'. For example, if we have one algorithm that runs in (0.225n^2 + 0.32) seconds and another that runs in (0.47n^2 + 0.01n) seconds, we would suggest that both of these are the same in respect to O notation. Since both cases have a quadratic run time we say that they are both O(n^2). In analyzing algorithms, computer scientists take three things into account: the best case, the worst case, and the average case. This is done to possibly consider how the algorithm should be implemented or improved, or simply to analyze its speed. If the algorithm involves dividing a problem into tasks (e..g, binary search) computer scientists assume log n. Therefore, we express this thought as O(lg n). If the amount of steps of an algorthm increases in proportion to the size of n we express this as O(n). If the task takes the same amount of time regardless of the case (best/worst) it is referred to as O(1)--or constant.

Selection sort works like this. For each list position in the list, loop through the entire list from that position to find the minimum item. If it smaller than the item at the current position, swap them. This algorithm is not so great. This sort is considered O(n^2). Recall, this means that the number of steps increases in proportion to the size of n, squared. With selection sort we can see that what makes it quadratic is the fact that it must do a full linear search of the list. We can conclude that there is a constant factor to this algorithm which insists it will take the same number of steps whatever the size. Therefore, best and worst case are the same.
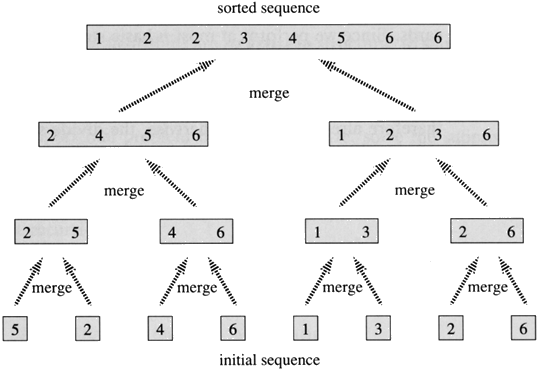
The other sort, merge sort, is more interesting. It divides the list into n sub lists each of at least length 1 and sorts that sub list. It repeatedly merges those sub lists to create a sorted sublists. This continues until you have a single sorted list. The image to the right illustrates this concept well. This is an example of O(n lg n) complexity (best and worst case). This is a result of using the "divide and conquer" method in which every split (which takes O(n) time) is reducing the size of the array (thus the load of work--this is where lg n comes from).
Big-O
Before looking at the algorithms I should establish an idea of what Big-O is (to my understanding) and how we use it to analyze algorithms.
Big-O attempts to take away the little details of mathematical analysis of something like sorting or searching and sum it up in an abstract notation of 'O'. For example, if we have one algorithm that runs in (0.225n^2 + 0.32) seconds and another that runs in (0.47n^2 + 0.01n) seconds, we would suggest that both of these are the same in respect to O notation. Since both cases have a quadratic run time we say that they are both O(n^2). In analyzing algorithms, computer scientists take three things into account: the best case, the worst case, and the average case. This is done to possibly consider how the algorithm should be implemented or improved, or simply to analyze its speed. If the algorithm involves dividing a problem into tasks (e..g, binary search) computer scientists assume log n. Therefore, we express this thought as O(lg n). If the amount of steps of an algorthm increases in proportion to the size of n we express this as O(n). If the task takes the same amount of time regardless of the case (best/worst) it is referred to as O(1)--or constant.
Sorting Algorithms
In class we discussed four sorting algorithms: the selections sort, insertion sort, quick sort, and merge sort. I will focus on two of them to demonstrate the differences that can come about in Big-O analysis (and to keep this short). In analyzing sorting algorithms, scientists always consider how well the algorithm scales with an increase of size. Algorithm A can have incredible performance for a list size of 100 compared to algorithm B. However, say we increase the size to 1 million. A's performance dramatically decreases while B's is much better. Thus, algorithm's are tested at small and extraordinary scales to ensure we are not being deceived.Selection sort works like this. For each list position in the list, loop through the entire list from that position to find the minimum item. If it smaller than the item at the current position, swap them. This algorithm is not so great. This sort is considered O(n^2). Recall, this means that the number of steps increases in proportion to the size of n, squared. With selection sort we can see that what makes it quadratic is the fact that it must do a full linear search of the list. We can conclude that there is a constant factor to this algorithm which insists it will take the same number of steps whatever the size. Therefore, best and worst case are the same.
The other sort, merge sort, is more interesting. It divides the list into n sub lists each of at least length 1 and sorts that sub list. It repeatedly merges those sub lists to create a sorted sublists. This continues until you have a single sorted list. The image to the right illustrates this concept well. This is an example of O(n lg n) complexity (best and worst case). This is a result of using the "divide and conquer" method in which every split (which takes O(n) time) is reducing the size of the array (thus the load of work--this is where lg n comes from).
Thoughts
It is interesting to get a glance at what real computer scientists that work on algorithms go through--what they consider when constructing an algorithm and how they may improve it. This notion has encouraged me to constantly pushing myself to consider if my implementations (in any instance) when I program are the most optimal. We should be asking ourselves as beginner programmers: what is it I can do to improve my implementation and how may I approach it?Monday 17 March 2014
Post #6 Catchup and A2
For the past few weeks we have dived further into abstract data types. We looked at linked lists, binary trees, and binary search trees. I had gotten sick for the binary tree lectures and fell behind by a little bit and I find myself still playing catchup with CSC and most of my other courses. However, my impressions of the abstract data structures are mostly good. They concepts themselves were easy to grasp, although it was difficult to grasp implementation of them.
This week A2 is due. The first part of A2 required us to create design a collection of classes for a "regex" tree. This was not as challenging as the second part of A2. I feel I spent a lot of time thinking about the (four) functions in part two more than I actually have coded. This assignment is significantly less fun than A1, but I feel it is a little hard, if not on par with its difficulty. So far A2 is going well, I have one function left (regex_match) and I am done!
This week A2 is due. The first part of A2 required us to create design a collection of classes for a "regex" tree. This was not as challenging as the second part of A2. I feel I spent a lot of time thinking about the (four) functions in part two more than I actually have coded. This assignment is significantly less fun than A1, but I feel it is a little hard, if not on par with its difficulty. So far A2 is going well, I have one function left (regex_match) and I am done!
Sunday 23 February 2014
#5 Recursion
A large concept that CSC148 revolves around is that of recursion. Most of our lecture's are focused on implementing recursion in order to simplify the task we are looking at, and also to make things more efficient. By definition, recursion is to define something in terms of itself" in order to simplify a task into smaller parts to achieve a goal. In programming, recursion is implementing by creating functions that call themselves. The best way to explain recursion is through examples:
Above is code for a function that finds the minimum number inside of a nested list. I will step you through a call on recursive_min([2, [1, 12]).
1. Loop over the list
2. i == 2 (not list) -> so append object to the list
3. list = [2] so far.
4. i == list so we call the function in itself (recursively)
1. Start over again and repeat.
2. Since there is no other nested list, this call will return the min number.
3. the min == 1.
4. This call returns 1, which is appended to the original list.
5. The original list now looks like this: [2, 1]
6. Notice, there is nothing left to loop over.
7. Return the min of the list, which is 1.
Therefore, the smallest number in the list is 1.
Notice, we have minimized this task to a single line of code using recursion. If we were to not use recursion, well, it wouldn't look pretty.

 A single Binary Tree is a tree that consists of a root and two children. However, using recursion we can extend the concept and create a larger tree that is made up of other binary nodes (as you can see below).
A single Binary Tree is a tree that consists of a root and two children. However, using recursion we can extend the concept and create a larger tree that is made up of other binary nodes (as you can see below).
How is this recursion? If we look back at our definition of recursion: something "defined in itself", we can see that this tree is exactly that.
The general tree is made up of smaller sub-binary nodes that can be looked at as singular. If we attempted to traverse through this tree, we would do so in smaller steps; one binary tree at a time.
Example #1
1. Loop over the list
2. i == 2 (not list) -> so append object to the list
3. list = [2] so far.
4. i == list so we call the function in itself (recursively)
1. Start over again and repeat.
2. Since there is no other nested list, this call will return the min number.
3. the min == 1.
4. This call returns 1, which is appended to the original list.
5. The original list now looks like this: [2, 1]
6. Notice, there is nothing left to loop over.
7. Return the min of the list, which is 1.
Therefore, the smallest number in the list is 1.
Notice, we have minimized this task to a single line of code using recursion. If we were to not use recursion, well, it wouldn't look pretty.
Example #2
Instead of an example of coding, we can also explain recursion using visuals. A Tree (the ADT I talked about last week) is a recursive data structure. When I was first introduced to trees, my understanding of recursion got much clearer. A single Binary Tree is a tree that consists of a root and two children. However, using recursion we can extend the concept and create a larger tree that is made up of other binary nodes (as you can see below).How is this recursion? If we look back at our definition of recursion: something "defined in itself", we can see that this tree is exactly that.
The general tree is made up of smaller sub-binary nodes that can be looked at as singular. If we attempted to traverse through this tree, we would do so in smaller steps; one binary tree at a time.
Thoughts on Recursion
Recursion is a very abstract concept that is something that you get right away or takes time to understand. For me, it took some time for the concept to finally click. In my opinion, following Danny's advice to attempt to trace the recursion on paper and to not think about recursion in its details is vital to understanding recursion.Sunday 16 February 2014
Post #4: Assignment I and Trees!
I forgot to post last week so I wanted to quickly mention that Assignment I is over! I finished it a week before the due date, so I had plenty of room to tweak everything. My overall thoughts are pretty positive, the assignment was an interesting concept and posed a challenged for the most part! The most difficult part was not actually coding, rather, it was the process of understanding how to approach the assignment (notably step 5). Other than that, I thought it was great and I managed to get it done!
 So this week (6) we briefly learned about the Tree ADT. By definition, they are a data structure in which data is linked through a hierarchy of linked nodes.
So this week (6) we briefly learned about the Tree ADT. By definition, they are a data structure in which data is linked through a hierarchy of linked nodes.
We also learned a bunch of terminology relevant to this ADT such as "leaf" (a node with no children--e.g. [12] in the image) and "root" (which distinguishes a node, e.g. [50]).
It is easier to think of tree recursively; a Tree is a collection of nodes (which has a value) that refers to children nodes (which also has a value). These children can either either create a new tree--recursively--or just be a leaf.
For example, if we look at the image to the left we can see that the first tree consists of the root [50] with children [17] and [76] -- recursively, we can see that [17] also is a root of a tree that has a two children.. and so on.
Trees can be accessed and manipulated by traversing through the data. What we learned in lecture were three methods of doing so:
In-order traversal -- Which recursively visit the left subtree, the root, then the right subtree.
Pre-order traversal -- Which recursively visits the root, the left subtree, then the right subtree.
Post-order traversal -- Which recursively visit the left subtree, then the right subtree, then the root.
Pretty cool stuff! Looking forward to understanding the implementation of trees.
It's reading week! Yay and Nay! Yay because I don't have to wake up at 6:30 to make my train, but nay because I have the most amount of work I've ever had in first year. An assignment for each course! Yup, assignment II has been announced. I've skimmed over it, but I haven't started. It seems like it involves implementing trees to work with regex regular expressions (which I am vaguely familiar with). We also have Test 1 coming up, I am pretty nervous but I think I will do well if I study what I am not great with (which I feel is recursion currently).
Good luck to me!
So this week (6) we briefly learned about the Tree ADT. By definition, they are a data structure in which data is linked through a hierarchy of linked nodes.We also learned a bunch of terminology relevant to this ADT such as "leaf" (a node with no children--e.g. [12] in the image) and "root" (which distinguishes a node, e.g. [50]).
It is easier to think of tree recursively; a Tree is a collection of nodes (which has a value) that refers to children nodes (which also has a value). These children can either either create a new tree--recursively--or just be a leaf.
For example, if we look at the image to the left we can see that the first tree consists of the root [50] with children [17] and [76] -- recursively, we can see that [17] also is a root of a tree that has a two children.. and so on.
Trees can be accessed and manipulated by traversing through the data. What we learned in lecture were three methods of doing so:
In-order traversal -- Which recursively visit the left subtree, the root, then the right subtree.
Pre-order traversal -- Which recursively visits the root, the left subtree, then the right subtree.
Post-order traversal -- Which recursively visit the left subtree, then the right subtree, then the root.
Pretty cool stuff! Looking forward to understanding the implementation of trees.
It's reading week! Yay and Nay! Yay because I don't have to wake up at 6:30 to make my train, but nay because I have the most amount of work I've ever had in first year. An assignment for each course! Yup, assignment II has been announced. I've skimmed over it, but I haven't started. It seems like it involves implementing trees to work with regex regular expressions (which I am vaguely familiar with). We also have Test 1 coming up, I am pretty nervous but I think I will do well if I study what I am not great with (which I feel is recursion currently).
Good luck to me!
Saturday 1 February 2014
Post #3: Assignment 1 and Week Overview
This post is focused on what we did this week, my thoughts on exercise 2, and my progress with Assignment 1.
This week's content was focused on recursion. Again, I know we have to write on recursion in detail during the seventh week, so I'll talk about my first impressions with recursion. I wasn't completely shocked bu the idea of recursion as I've heard of it but never engaged in it, but after the lectures I was really intrigued by the concept. I did have a few problems initially understanding in the first few examples that Prof Heap gave us in the beginning. This was mainly because of the code that was being used. Heap advocates for list comprehensions and ternary statements--which are fantastic, but I don't feel it is the best way to introduce recursion, I feel if he showed us the iterative version, than the condensed version, I would have had a clearer understanding initially.
Moving on to exercise 2. Overall, the exercise was pretty easy, I spent about 30 minutes in total and it wasn't overwhelming at all. It was a simple exercise that dealt with raising and catching exceptions. Although it was easy, it gave me a helpful reminder of the usefulness of catching exceptions for A1.

With that being said, I also wanted to mention my impressions and progress with Assignment 1. The assignment requires us to implement a model and controller for a "model-view-controller" program that it pretty much Towers of Hanoi with cheese and stools.
When the assignment was released I took some time to read the instructions and get a clear idea of what was expected. Something I noticed immediately was that this assignment compared to 108 assignments are completely different; it was much more vague and less technical and structured. You are expected to make an abstract idea into code. This is great! I love that we have more freedom and a room for some creativity.
Up to today, I've finished 70% of the assignment. I took it slow and went over my code multiple times before moving on to the next steps. I noticed that almost all the concepts we have learned so far are included in the assignment: ADT's, Classes, Recursion, and Exceptions.
I feel this assignment is aimed at teaching the student to understand how to understand other people's code and how (if you were hired to do work) to implement your code with theirs.
I started early on purpose because I knew that the final portion of the assignment involves a recursive function. I wanted to strengthen my understanding of recursion before moving on, which I have. Tom morrow I will be starting the final two steps of the assignment.
This week's content was focused on recursion. Again, I know we have to write on recursion in detail during the seventh week, so I'll talk about my first impressions with recursion. I wasn't completely shocked bu the idea of recursion as I've heard of it but never engaged in it, but after the lectures I was really intrigued by the concept. I did have a few problems initially understanding in the first few examples that Prof Heap gave us in the beginning. This was mainly because of the code that was being used. Heap advocates for list comprehensions and ternary statements--which are fantastic, but I don't feel it is the best way to introduce recursion, I feel if he showed us the iterative version, than the condensed version, I would have had a clearer understanding initially.
Moving on to exercise 2. Overall, the exercise was pretty easy, I spent about 30 minutes in total and it wasn't overwhelming at all. It was a simple exercise that dealt with raising and catching exceptions. Although it was easy, it gave me a helpful reminder of the usefulness of catching exceptions for A1.
With that being said, I also wanted to mention my impressions and progress with Assignment 1. The assignment requires us to implement a model and controller for a "model-view-controller" program that it pretty much Towers of Hanoi with cheese and stools.
When the assignment was released I took some time to read the instructions and get a clear idea of what was expected. Something I noticed immediately was that this assignment compared to 108 assignments are completely different; it was much more vague and less technical and structured. You are expected to make an abstract idea into code. This is great! I love that we have more freedom and a room for some creativity.
Up to today, I've finished 70% of the assignment. I took it slow and went over my code multiple times before moving on to the next steps. I noticed that almost all the concepts we have learned so far are included in the assignment: ADT's, Classes, Recursion, and Exceptions.
I feel this assignment is aimed at teaching the student to understand how to understand other people's code and how (if you were hired to do work) to implement your code with theirs.
I started early on purpose because I knew that the final portion of the assignment involves a recursive function. I wanted to strengthen my understanding of recursion before moving on, which I have. Tom morrow I will be starting the final two steps of the assignment.
Wednesday 22 January 2014
Post #2: Object Oriented Programming
I remember attempting to learn some Python during the summer in order to prepare for whatever was going to be thrown my way in first year. During this time, I was doing Zed Shaw's LearnPythonTheHardWay and I found myself suddenly being introduced to Object Oriented Programming, or OOP as it is referred to. Shaw opened with this paragraph:
Back to the programming world, OOP consist of classes (the object) and methods (the attributes). A class is a blueprint of whatever you want to create, in this blueprint you must create methods to give meaning, procedure, and functionality to your class. Surprisingly, you, programming in Python (and other OOP languages) live in a world of classes. Every Python method you use is a part of a class, like
So, what's the big deal about OOP? The big deal is that it allows for great opportunities that allow a developer to increase the size and complexity of his program. OOP encourages creativity for developers to create new classes that can have real world application.
So this is the blueprint for the class Stack which can be eventually used in the same manner
When you create a Stack object, it initializes a new "Stack of rocks" by creating an empty list which _rocks refers to.
Now what I have done is added meaning and functionality to the class by giving Stack attributes:
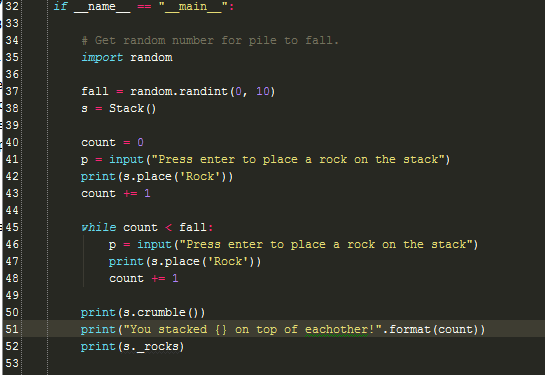
Now let's see our class in action. What this code does is selects a random number from 0-10. This number will per-determine the time a rock Stack crumbles (if the number is 4, it will crumble on the 4th rock).
Next, we create the Stack and start to stack rocks on top of each other, keeping track of how many rocks have been placed using the count variable.
Once the number of rocks that have been placed in the stack is equal to the fall variable, the stack of rocks crumble and the game is over. Finally, you get a message telling you how high your stack was.
 This is the output we get in one run of the game. Pretty cool eh?
This is the output we get in one run of the game. Pretty cool eh?
Remember, you don't have to stick to the game. The great thing about classes is that you can do whatever you want with them! You can add more functionality, increase the complexity of the class, and increase its application to the real world.
The final thing I want to mention about OOP is inheritance. Inheritance is used to indicate that one class will get most or all of its features from a parent class.What I didn't mention above is what part inheritance plays in the Stack class.
When we create a class in Python, the class, by default, inherits the object class which includes a bunch of stuff, but most notably the built-in functions of Python. So declaring
"I am now going to try to teach you the beginnings of object-oriented programming, classes, and objects using what you already know about dictionaries and modules. My problem though is that object-oriented programming (aka OOP) is just plain weird. You have to simply struggle with this, try to understand what I say here, type in the code, and then in the next exercise I'll hammer it in."Now, this was pretty discouraging when I first read it, mainly because of the use of the word "try." In short, my initial impression of OOP was a rather negative one, that is until I started learning it.
What is Object-Oriented Programming?
Object oriented programming is a procedural programming paradigm that focuses on the creation of objects which consist of attributes that both describe the object and give it a function. To illustrate this in the real world: a rock is an object that has multiple attributes: it can be solid, it may be small or extraordinarily large. However, this rock also has functionality, you may use it as a tool to create a fire, a weapon, or maybe just to stack on top of other rocks as a game.Back to the programming world, OOP consist of classes (the object) and methods (the attributes). A class is a blueprint of whatever you want to create, in this blueprint you must create methods to give meaning, procedure, and functionality to your class. Surprisingly, you, programming in Python (and other OOP languages) live in a world of classes. Every Python method you use is a part of a class, like
str, int, float, and list. So, what's the big deal about OOP? The big deal is that it allows for great opportunities that allow a developer to increase the size and complexity of his program. OOP encourages creativity for developers to create new classes that can have real world application.
How do I Become Object-Oriented?
So we are going to make a Stack class that simulates the rock stacking game I mentioned earlier. (For sake of simplification, I am not going to consider the problems that have been mentioned in lecture as of Week 3. Also, I am going to insert picture of code instead of using the </code> tag with Blogger because I don't like how it looks.) I also am not going to be going over Python syntax, rather I will just explain the class in plain English so we can comprehend OOP.The Stack Class:
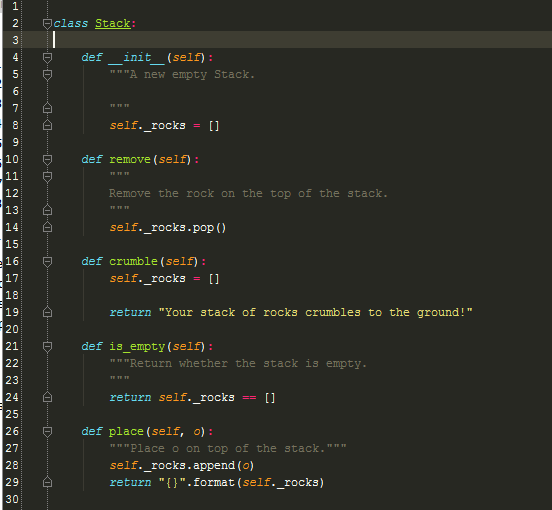 |
So this is the blueprint for the class Stack which can be eventually used in the same manner
list or str is. What we can see is the following:When you create a Stack object, it initializes a new "Stack of rocks" by creating an empty list which _rocks refers to.
Now what I have done is added meaning and functionality to the class by giving Stack attributes:
- remove -- which removes a rock from the top of the stack.
- crumble -- which crumbles a Stack of rocks
- is_empty -- which checks if the Stack of rocks is empty.
- place -- of course we need a method that places a rock on the top of the stack.
Implementing the game:
Now let's see our class in action. What this code does is selects a random number from 0-10. This number will per-determine the time a rock Stack crumbles (if the number is 4, it will crumble on the 4th rock).
Next, we create the Stack and start to stack rocks on top of each other, keeping track of how many rocks have been placed using the count variable.
Once the number of rocks that have been placed in the stack is equal to the fall variable, the stack of rocks crumble and the game is over. Finally, you get a message telling you how high your stack was.
Remember, you don't have to stick to the game. The great thing about classes is that you can do whatever you want with them! You can add more functionality, increase the complexity of the class, and increase its application to the real world.
Inheritance
The final thing I want to mention about OOP is inheritance. Inheritance is used to indicate that one class will get most or all of its features from a parent class.What I didn't mention above is what part inheritance plays in the Stack class.
When we create a class in Python, the class, by default, inherits the object class which includes a bunch of stuff, but most notably the built-in functions of Python. So declaring
Stack is the same as declaring Stack(object). If you look carefully, you can see that we have used the inherited methods from object; append and pop. NewClass(Stack). NewClass will inherit all the attributes of Stack in the same manner Stack inherits from object. Actions on NewClass imply an action on Stack. When we do so, we have the ability to override the actions of the class by creating class with the same name. In doing this we have allowed for a new opportunity of complexity of our class.
Subscribe to:
Posts (Atom)